Example 2: HKR classifier on toy dataset¶
![]()
In this notebook, we show how to build a robust classifier based on the
regularized version of the Kantorovitch-Rubinstein duality. We use the
two moons synthetic dataset for our experiments.
# Install the required library deel-torchlip (uncomment line below)
# %pip install -qqq deel-torchlip
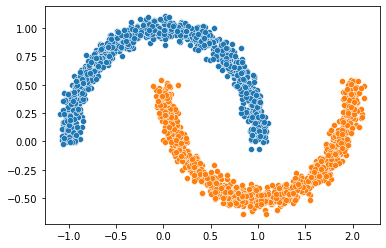
1. Two moons dataset¶
We first build our two moons dataset.
from sklearn.datasets import make_moons, make_circles # the synthetic dataset
circle_or_moons = 1 # 0 for circle, 1 for moons
n_samples = 5000 # number of sample in the dataset
noise = 0.05 # amount of noise to add in the data. Tested with 0.14 for circles 0.05 for two moons
factor = 0.4 # scale factor between the inner and the outer circle
if circle_or_moons == 0:
X, Y = make_circles(n_samples=n_samples, noise=noise, factor=factor)
else:
X, Y = make_moons(n_samples=n_samples, noise=noise)
# When working with the HKR-classifier, using labels {-1, 1} instead of {0, 1} is advised.
# This will be explained later on.
Y[Y == 1] = -1
Y[Y == 0] = 1
import seaborn as sns
X1 = X[Y == 1]
X2 = X[Y == -1]
sns.scatterplot(x=X1[:1000, 0], y=X1[:1000, 1])
sns.scatterplot(x=X2[:1000, 0], y=X2[:1000, 1])
<Axes: >
2. Relation with optimal transport¶
In this setup we can solve the optimal transport problem between the
distribution of X[Y==1] and X[Y==-1]. This usually requires to
match each element of the first distribution with an element of the
second distribution such that this minimizes a global cost. In our setup
this cost is the distance, which will allow us to make use
of the KR dual formulation. The overall cost is then the
distance.
2.1. Wasserstein distance¶
The wasserstein distance measures the distance between two probability distributions. The Wikipedia article gives a more intuitive definition of it:
Intuitively, if each distribution is viewed as a unit amount of “dirt” piled on , the metric is the minimum “cost” of turning one pile into the other, which is assumed to be the amount of dirt that needs to be moved times the mean distance it has to be moved. Because of this analogy, the metric is known in computer science as the earth mover’s distance.
Mathematically it is defined as
where is the set of all probability measures on with marginals and . In most cases, this equation is not tractable.
2.2. KR dual formulation¶
The Kantorovich-Rubinstein (KR) dual formulation of the Wasserstein distance is
This states the problem as an optimization problem over the space of 1-Lipschitz functions. We can estimate this by optimizing over the space of 1-Lipschitz neural networks.
2.3. Hinge-KR loss¶
When dealing with , we usually try to optimize the maximization problem above without taking into account the actual classification task at hand. To improve robustness for our task, we want our classifier to be centered in 0, which can be done without altering the inital problem and its Lipschitz property. By doing so we can use the obtained function for binary classification, by looking at the sign of .
In order to enforce this, we will add a Hinge term to the loss. It has been shown that this new problem is still a optimal transport problem and that this problem admit a meaningfull optimal solution.
2.4. HKR classifier¶
Now we will show how to build a binary classifier based on the regularized version of the KR dual problem.
In order to ensure the 1-Lipschitz constraint, torchlip uses
spectral normalization. These layers can also use Björk
orthonormalization to ensure that the gradient of the layer is 1 almost
everywhere. Experiment shows that the optimal solution lies in this
sub-class of functions.
import torch
from deel import torchlip
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Other Lipschitz activations are ReLU, MaxMin, GroupSort2, GroupSort.
wass = torchlip.Sequential(
torchlip.SpectralLinear(2, 256),
torchlip.FullSort(),
torchlip.SpectralLinear(256, 128),
torchlip.FullSort(),
torchlip.SpectralLinear(128, 64),
torchlip.FullSort(),
torchlip.FrobeniusLinear(64, 1),
).to(device)
wass
Sequential(
(0): ParametrizedSpectralLinear(
in_features=2, out_features=256, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): _SpectralNorm()
(1): _BjorckNorm()
)
)
)
(1): FullSort()
(2): ParametrizedSpectralLinear(
in_features=256, out_features=128, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): _SpectralNorm()
(1): _BjorckNorm()
)
)
)
(3): FullSort()
(4): ParametrizedSpectralLinear(
in_features=128, out_features=64, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): _SpectralNorm()
(1): _BjorckNorm()
)
)
)
(5): FullSort()
(6): ParametrizedFrobeniusLinear(
in_features=64, out_features=1, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): _FrobeniusNorm()
)
)
)
)
As we can see, the network has a gradient equal to 1 almost everywhere as all the layers respect this property.
It is good to note that the last layer is a FrobeniusLinear because,
with a single output, it becomes equivalent to normalize the Frobenius
norm and the spectral norm (as we only have a single singular value).
2.5. Learn classification on toy dataset¶
Now we are ready to learn the classification task on the two moons dataset.
from deel.torchlip import KRLoss, HKRLoss, HingeMarginLoss
batch_size = 256
n_epochs = 10
alpha = 0.98
min_margin = 0.29 # minimum margin to enforce between the values of F for each class
kr_loss = KRLoss()
hkr_loss = HKRLoss(alpha=alpha, min_margin=min_margin)
hinge_margin_loss =HingeMarginLoss(min_margin=min_margin)
optimizer = torch.optim.Adam(lr=0.01, params=wass.parameters())
loader = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(torch.tensor(X).float(), torch.tensor(Y).float()),
batch_size=batch_size,
shuffle=True,
)
for epoch in range(n_epochs):
m_kr, m_hm, m_acc = 0, 0, 0
for step, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = wass(data)
loss = hkr_loss(output, target)
loss.backward()
optimizer.step()
m_kr += kr_loss(output, target)
m_hm += hinge_margin_loss(output, target)
m_acc += (
torch.sign(output.view(target.shape)) == torch.sign(target)
).sum() / len(target)
print(f"Epoch {epoch + 1}/{n_epochs}")
print(
f"loss: {loss:.04f} - "
f"KR: {m_kr / (step + 1):.04f} - "
f"hinge: {m_hm / (step + 1):.04f} - "
f"accuracy: {m_acc / (step + 1):.04f}"
)
Epoch 1/10
loss: 0.0504 - KR: 0.0614 - hinge: 0.1179 - accuracy: 0.6261
Epoch 2/10
loss: 0.0248 - KR: 0.3622 - hinge: 0.0339 - accuracy: 0.8957
Epoch 3/10
loss: -0.0085 - KR: 0.4284 - hinge: 0.0083 - accuracy: 0.9838
Epoch 4/10
loss: -0.0110 - KR: 0.5243 - hinge: 0.0010 - accuracy: 1.0000
Epoch 5/10
loss: -0.0136 - KR: 0.6442 - hinge: 0.0010 - accuracy: 0.9998
Epoch 6/10
loss: -0.0124 - KR: 0.7111 - hinge: 0.0011 - accuracy: 1.0000
Epoch 7/10
loss: -0.0147 - KR: 0.7326 - hinge: 0.0010 - accuracy: 0.9992
Epoch 8/10
loss: -0.0146 - KR: 0.7773 - hinge: 0.0013 - accuracy: 0.9998
Epoch 9/10
loss: -0.0136 - KR: 0.7876 - hinge: 0.0011 - accuracy: 1.0000
Epoch 10/10
loss: -0.0158 - KR: 0.7917 - hinge: 0.0010 - accuracy: 0.9994
2.6. Plot output countour line¶
As we can see, the classifier gets a pretty good accuracy. We now look at the actual function. Since we are in a two-dimensional space, we can draw a countour plot to visualize .
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(X[:, 0].min() - 0.2, X[:, 0].max() + 0.2, 120)
y = np.linspace(X[:, 1].min() - 0.2, X[:, 1].max() + 0.2, 120)
xx, yy = np.meshgrid(x, y, sparse=False)
X_pred = np.stack((xx.ravel(), yy.ravel()), axis=1)
# Make predictions from F:
Y_pred = wass(torch.tensor(X_pred).float().to(device))
Y_pred = Y_pred.reshape(x.shape[0], y.shape[0]).detach().cpu().numpy()
# We are also going to check the exported version:
vwass = wass.vanilla_export()
Y_predv = vwass(torch.tensor(X_pred).float().to(device))
Y_predv = Y_predv.reshape(x.shape[0], y.shape[0]).detach().cpu().numpy()
# Plot the results:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 6))
sns.scatterplot(x=X[Y == 1, 0], y=X[Y == 1, 1], alpha=0.1, ax=ax1)
sns.scatterplot(x=X[Y == -1, 0], y=X[Y == -1, 1], alpha=0.1, ax=ax1)
cset = ax1.contour(xx, yy, Y_pred, cmap="twilight", levels=np.arange(-1.2, 1.2, 0.4))
ax1.clabel(cset, inline=1, fontsize=10)
sns.scatterplot(x=X[Y == 1, 0], y=X[Y == 1, 1], alpha=0.1, ax=ax2)
sns.scatterplot(x=X[Y == -1, 0], y=X[Y == -1, 1], alpha=0.1, ax=ax2)
cset = ax2.contour(xx, yy, Y_predv, cmap="twilight", levels=np.arange(-1.2, 1.2, 0.4))
ax2.clabel(cset, inline=1, fontsize=10)
<a list of 5 text.Text objects>
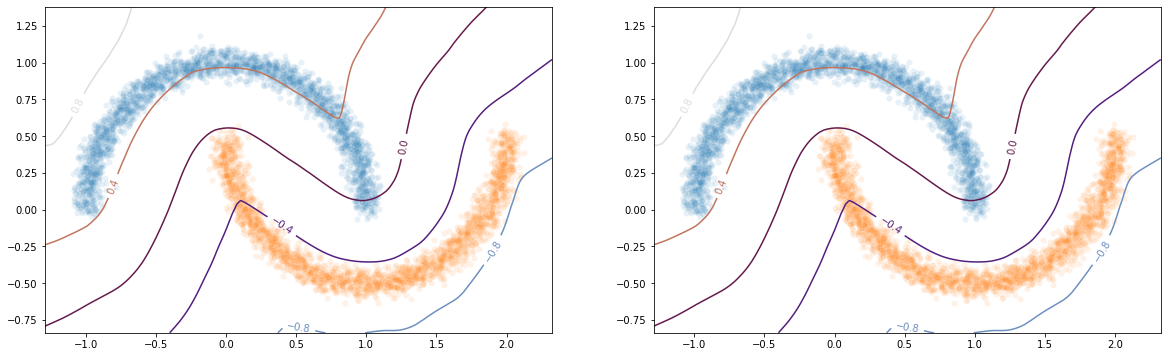
The vanilla_export() method allows us to obtain a torch module
without the overhead from the 1-Lipschitz constraints after training.